- Get TK4- MVS Sofware
- Get wc3270 Terminal Emulator
- Install wc3270 Terminal Emulator
- Install and Run MVS 3.8j
- Logging In to/Out of MVS 3.8j
- Shutting down MVS 3.8j from TSO
- Using TSO RFE Application
- Adding a User
- Creating Datasets
- JCL Overview
- Your First Cobol Program
- Your First Assembler Program
- Your First Fortran Program
- Your First PL/1 Program
Your First COBOL Program
The name COBOL is an acronym for "common business-oriented language". COBOL was one of the first programming languages. In fact the only languages older than COBOL are FORTRAN, LISP, and ALGOL. COBOL was basically designed by a committee and as its name implies is a business oriented language, you wouldn't want to design missle systems with COBOL. The version of COBOL that is available with MVS 3.8J is COBOL 65.
The program being developed here is a simple COBOL program and will give a quick introduction to the essential parts of the language.
Creating a source dataset

As this is the first time in these lessons where actual development will take place we step back a step and create a partitioned dataset to save our COBOL programs. Going into RFE take option 3 to bring up the utilities menu.

Once the utilities menu is displayed, take option 2 to work with datasets.
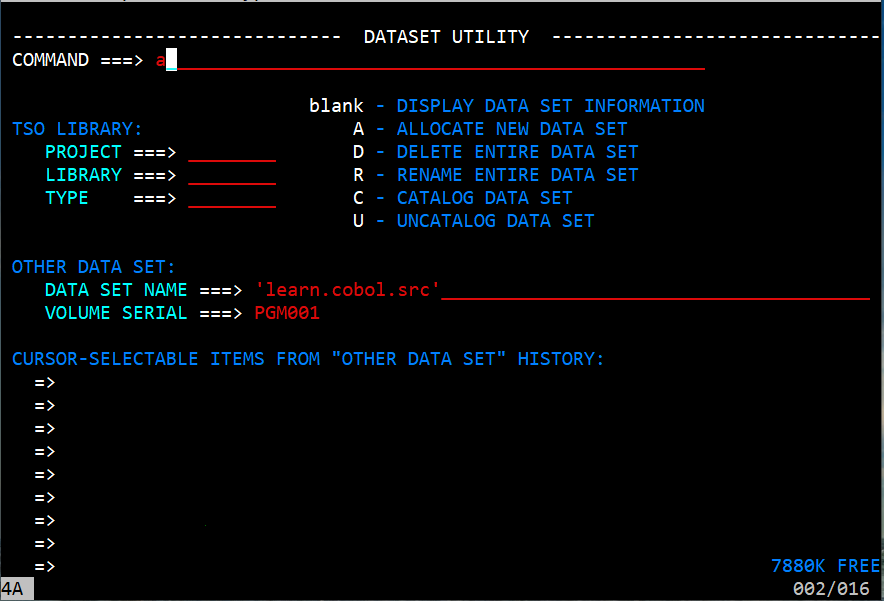
On the dataset screen, in the Command ===> input area enter an a since we will be allocating a new dataset.
In the Data Set Name area enter 'learn.cobol.src' including the single quotes.
In the Volume Serial area enter the volume where you want the dataset to be placed. Enter PUB010 or PUB011. In the displayed image PGM001 has been chosen. That is a volume that has been added to the system and is not part of the provided system. Adding a volume to the system will be discribed in a later lesson. Press enter to proceed to the dataset creation menu.

On this screen enter FB in the record format. Give it a record size of 80 and a multiple of 80 in the physical block size. Allocation can be in tracks or cylinders. The initial size is 5 cyclinders with a secondary space of 3 and number of directory blocks as 4. This may or may not be optimal for what we are doing.
After you are satisfied with your values, press enter.

After enter is pressed the data set utility screen is displayed and in the upper left corner it will say 'Data set created'.
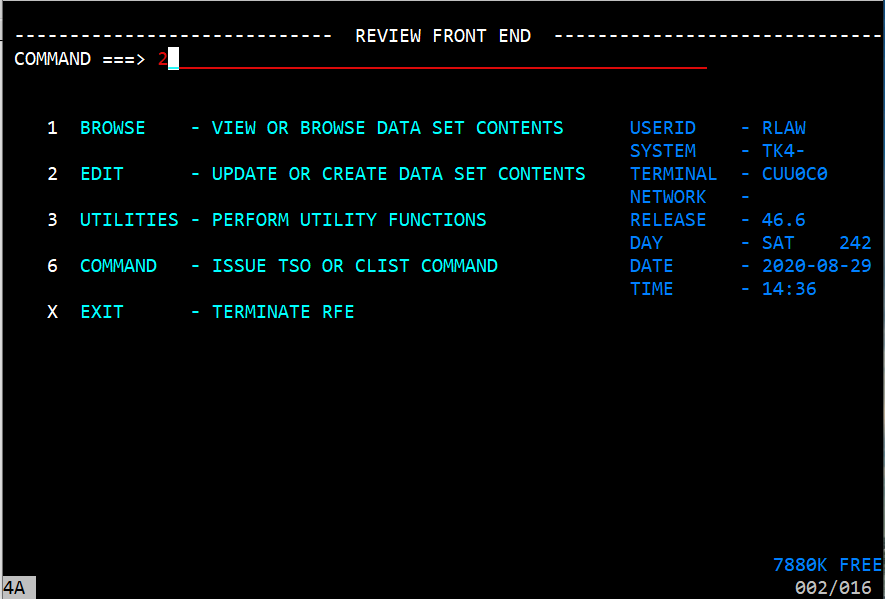
Go back to the Review Front End and select option 2 for EDIT.
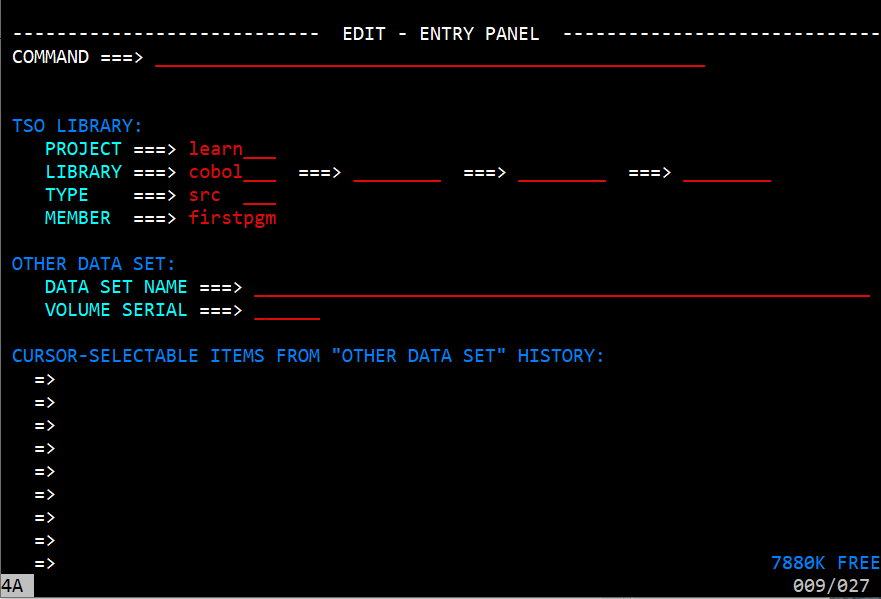
On the Edit Entry Panel you enter the values that allow the program to identify the partitioned dataset you are going to edit. Enter the values shown on the image. Notice that there is a correlation between 'learn.cobol.src' which is the partitioned dataset that was created. You will find later that we will reference learn.cobol.src(firstpgm). After you have entered the values press enter to bring up the member edit screen.

When the source member is first displayed it is empty and the entire screen is available for input. When the enter key is pressed, the lines that do not have anything in them will disappear. The screen is divided into three areas. 1. The command line, 2. The command section/lines numbers on each individual line (the six dots), 3. The input area where we can write code.
Code Sections
Each COBOL program consists of four divisions, Identification Division, Environment Division, Data Division, and Procedure Division. Each of these divisions may also have sections, which have paragraphs, which have sentences. This will make more sense as we progress.
Identification Division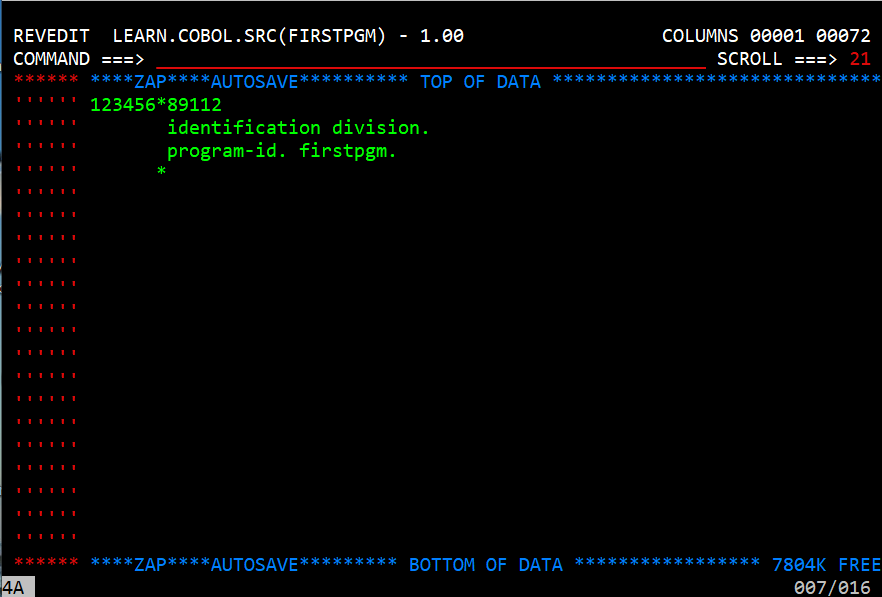
In the above image the first line is a comment showing the column numbers significant to COBOL. It is not necessary but I entered it there to make it easier to tell where column 8 and column 12 begin. The asterisk in column 7 means this is a comment line. The following line says 'identification division.' The following that says 'program-id. firstpgm.'. Notice the periods, they are required. Both the identification division and the program-id lines are required in this version of COBOL. Notice they are written in lower case. Now press the enter key.
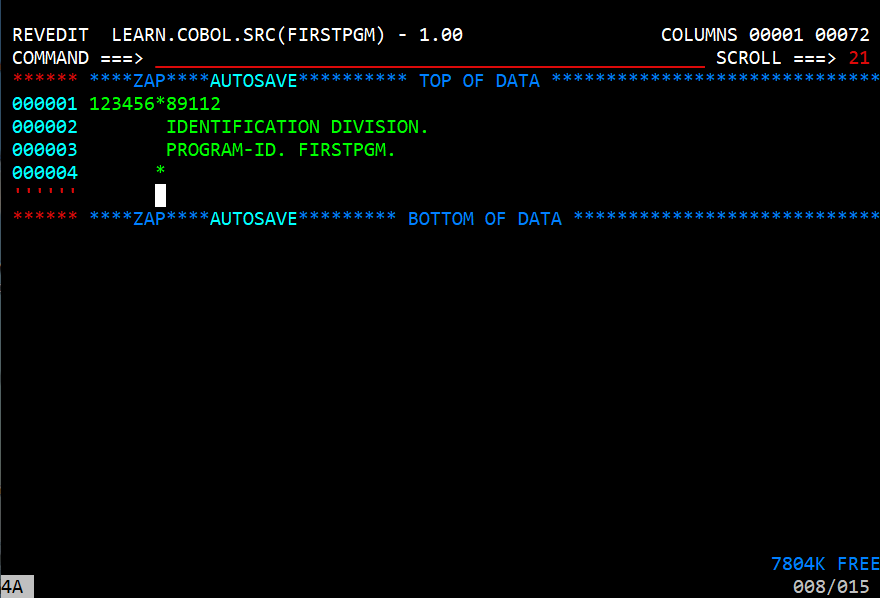
Notice that the extra lines have been deleted and that the characters are now upper case. This version of COBOL requires that they are in upper case. In fact almost everything in COBOL is upper case
On the last line enter 'i' and press enter. That will open a single line for input immediately after the line you entered the 'i' on. If you enter 'i10' it will insert 10 blank lines.
There are other paragraphs that may be used in the identification division. They are:
- AUTHOR
- INSTALLATION
- DATE-WRITTEN
- DATE-COMPILED
- SECURITY
- REMARKS
There is one interesting thing about the DATE-COMPILED paragraph. If you do not put a sentence on the line, when the program is compiled, if you have it list the compiled source, the date it was compiled will be inserted.
Environment Division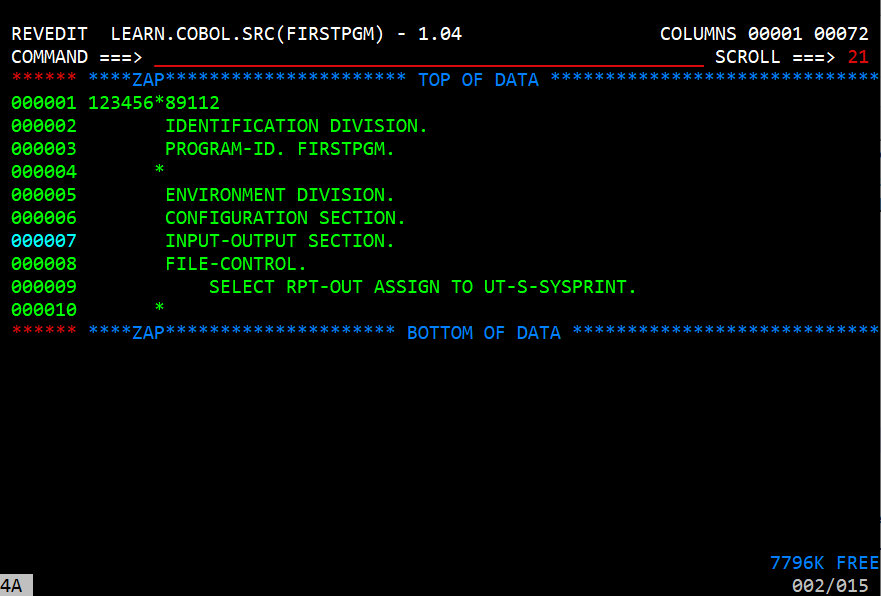
The Environment Division describes how the program communicates with the physical parts of the computer. Start by entering a line saying 'ENVIRONMENT DIVISION.' It must begin in column 8. The next line is 'CONFIGURATION SECTION.' Within the Configuratio Section there are three paragraphs.
- SOURCE-COMPUTER.
- OBJECT-COMPUTER.
- SPECIAL-NAMES.
All three of these lines are optional. Source-computer and Object-computer are optional but if used are supposed to identify the computer with a sentence such as IBM-370. Special-names is a paragraph that is used when you are going to access certain things by another word. One of these is 'CONSOLE is CNSL.' This renames the CONSOLE to the work CNSL.
After the CONFIGURATION SECTION the ENVIRONMENT DIVISION has another section dealing files named INPUT-OUTPUT SECTION. This section has to control paragraphs
- FILE-CONTROL.
- I-O-CONTROL.
We will only cover FILE-CONTROL. The FILE-CONTROL is where the definitions of files
used in the program are entered. The program we are writing referenced in the JCL as
SYSPRINT. In the program we reference the file using the work RPT-OUT but it could be any
name desired. The format is SELECT
- 'UR' - card reader, card punch, or printer
- 'UT' - tape drive, disk drive, (printer also works
- 'DA' - Disk Drive - direct access such as ISAM or VSAM
The second section has these values:
Given the above definitins we can tell that the UT-S-SYSPRINT is a tape, disk drive, or printer that whose records are accessed sequentially, and are defined further in a JCL DD statement that is named SYSPRINT.
For certain file types, such as ISAM, there are additional phrases that are used in the select statement. They will be covered when we write a program using ISAM.
Data Division
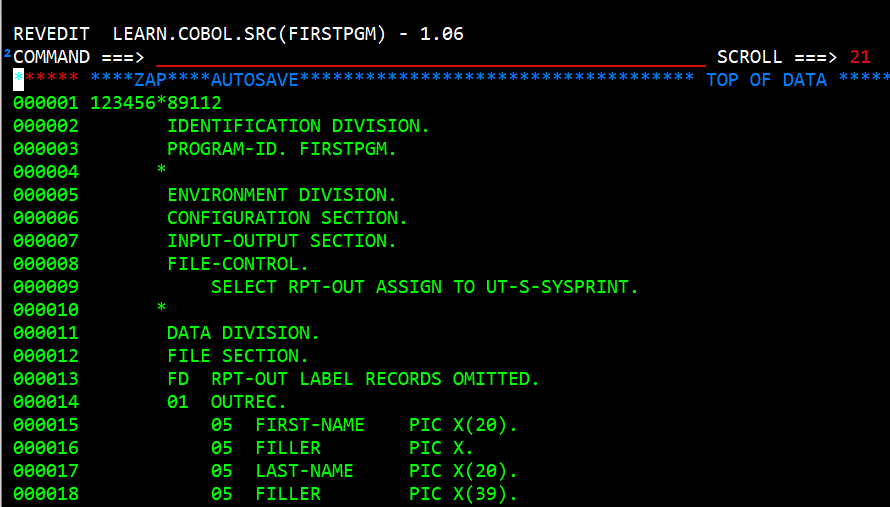
The Data Division has three sections.
- FILE SECTION.
- LINKAGE SECTION.
- WORKING-STORAGE SECTION
At this time we will cover the FILE SECTION and WORKING-STORAGE SECTION. The LINKAGE SECTION will be covered when we write a sub program.
The FILE SECTION is used to describe the files that are defined in the FILE-CONTROL in the Environment Division. This is done by having an FD entry. The line starts out with 'FD' in column 8 followed by two spaces followed by the SELECT filename in the FILE-CONTROL entry. This is normally followed by a defintion of the LABEL RECORDS. In this example we do not have any LABEL RECORDS so we say LABEL RECORDS OMITTED.
Next we define the record or records that exist in the file. This record is made up of group items. In
this example we only have one group item and that is OUTREC. Outrec has a number of sub-items that since
outrec is a level 01 and is followed by four 05 items that are subitems. Each group item can be subdivided
into subitems when it is advantageous. For example we could have the following:
05 BIRTH-DATE.
10 BIRTH-MONTH PIC 99.
10 BIRTH-DAY PIC 99.
10 BIRTH-YEAR PIC 9(4).
Notice that the group item does not have a picture clause while its sub items must have a picture clause. In code we could reference BIRTH-DATE which would be an eight digit field. We could also reference BIRTH-MONTH, BIRTH-DAY, and BIRTH-YEAR as individual fields.
WORKING-STORAGE SECTION
The WORKING-STORAGE section is where we define other field and groups of fields that we need in the processing of the program. We can define individual fields that are not sub grouped with a level id of '77'. A level 77 is not a sub group either. There are also fields that have a level id of 66 and 88. 66 is used in redefining fields and will not be covered. 88 is used for a condition field and it will be covered in one of the programs.
PROCEDURE DIVISION
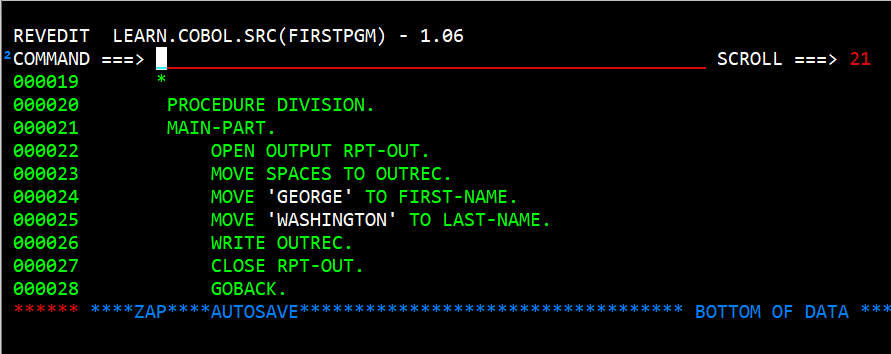
The PROCEDURE DIVISION is where the logic of the program is written. The PROCEDURE DIVISION starts with the words PROCEDURE DIVISION. Following lines consist of paragraphs and sentences. A paragraph starts in the A section of the line (colums 8-11) and ends with a period. Following a paragraph name the sentences are written. The start in the B section (12-72). These normally start with a verb followed by variable names and other keywords.
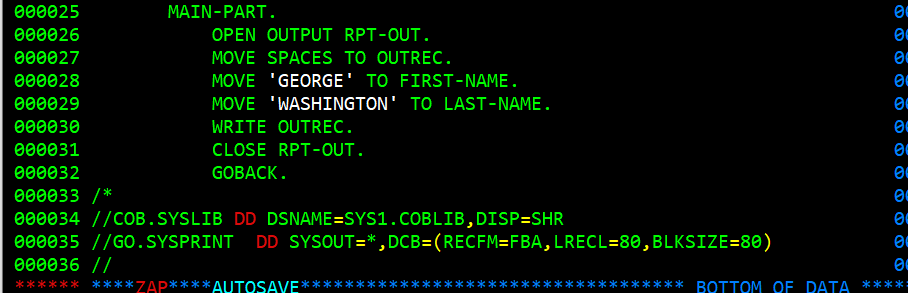
In the above image you can see a paragraph named MAIN-PART. That paragraph has seven sentences. On line 21 says OPEN OUTPUT RPT-OUT. It opens the file RPT-OUT for output. The next statement, line 22, moves spaces to the OUTREC variable. Lines 23 and 24 move GEORGE WASHINGTON to the variables FIRST-NAME and LAST-NAME. It might seem strange that line 25 writes a record but not a file. Since the variable OUTREC is an 01 variable and part of the FILE SECTION, and is part of the file descriptor RPT-OUT, it knows that OUTREC is written to the file RPT-OUT. Line 26 closes the file and makes in ineligible for any more writing. The next statement line 27 says GOBACK. It could also say STOP RUN and both of them will terminate the program. The difference is that if this program were called by another COBOL program GOBACK would terminate the subprogram and return to the calling program. STOP RUN terminates the entire COBOL program.
Compile, Link, and Go
Now that we have a dataset member containing our COBOL program we are not finished. We need a way to compile the source, link it with any link modules that are needed and execute the resulting program. There are two ways that will be discussed here on how to accomplish the compile, link, and go.
- JCL Job Stream with embedded source
- JCL Job Stream with external source
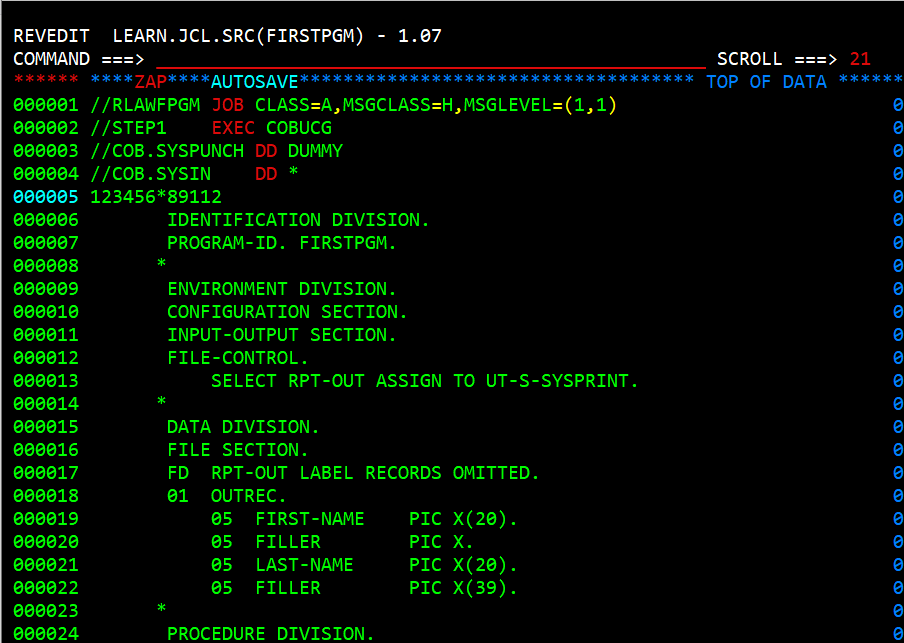
When the source code is embedded in a jcl job steam then the DD that references the input for the compile step is coded as a "here" document. Notice line 4 in the above images. It says //COB.SYSIN DD *. This statement means that in the COB step (which is part of the exec procedure) has a SYSIN DD that this job stream is providing as in instream dataset. This is done in lines 5 - 32 followed by a line that says /* which means end of instream dataset.
The last three lines of the file are specifying where the COB step SYSLIB data set is. In this case it is a library of compiled routines in SYS1.COBLIB and that file has a DISP=SHR which is saying that while this job is reading the COBLIB library other jobs can also. The next to last line (line 35) is for the GO step of the job and is referenced in programs as the SYSPRINT file. Notice line 12 of the program where is defines that the file RPT-OUT in the COBOL program is externally SYSPRINT. The GO.SYSPRINT jcl statement says the the output is based on the job parameters and its DCB (DATA CONTROL BLOCK) is Fixed Block A, record length is 80, and block size is 80. And this line is followed by line 36 which marks the end of the job stream.
The advantage to have the COBOL source as a "here" document in the job stream is that you can modify the source, save it, and submit it all on one screen.
External Source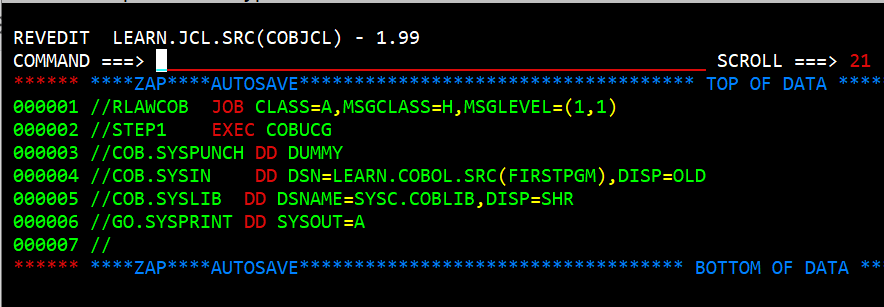
When the JCL and the COBOL source are in seperate datasets the COB.SYSIN DD is similar to the following:
//COB.SYSIN DD DSN=LEARN.COBOL.SRC(FIRSTPGM),DISP=OLDThe advantage to having the JCL seperate from the COBOL source is that there is only one copy of the JCL and it is reusable with changing the COB.SYSIN DSN name. Also, if the COBOL program was large, as many of them are it is easier to have the COBOL progam seperate and the steps to build would be standard for all programs.
JCL with embedded COBOL